The pharmaceutical industry stands at an inflection point. For years, the prevailing wisdom suggested that bigger AI models trained on more data would solve drug discovery challenges. Companies poured billions into computational infrastructure, racing to build ever-larger language models in the belief that scale alone would unlock the mysteries of molecular biology. Yet emerging evidence reveals a starkly different story: smaller, domain-specific AI systems are consistently outperforming massive general-purpose models across every critical metric that matters in pharmaceutical research.
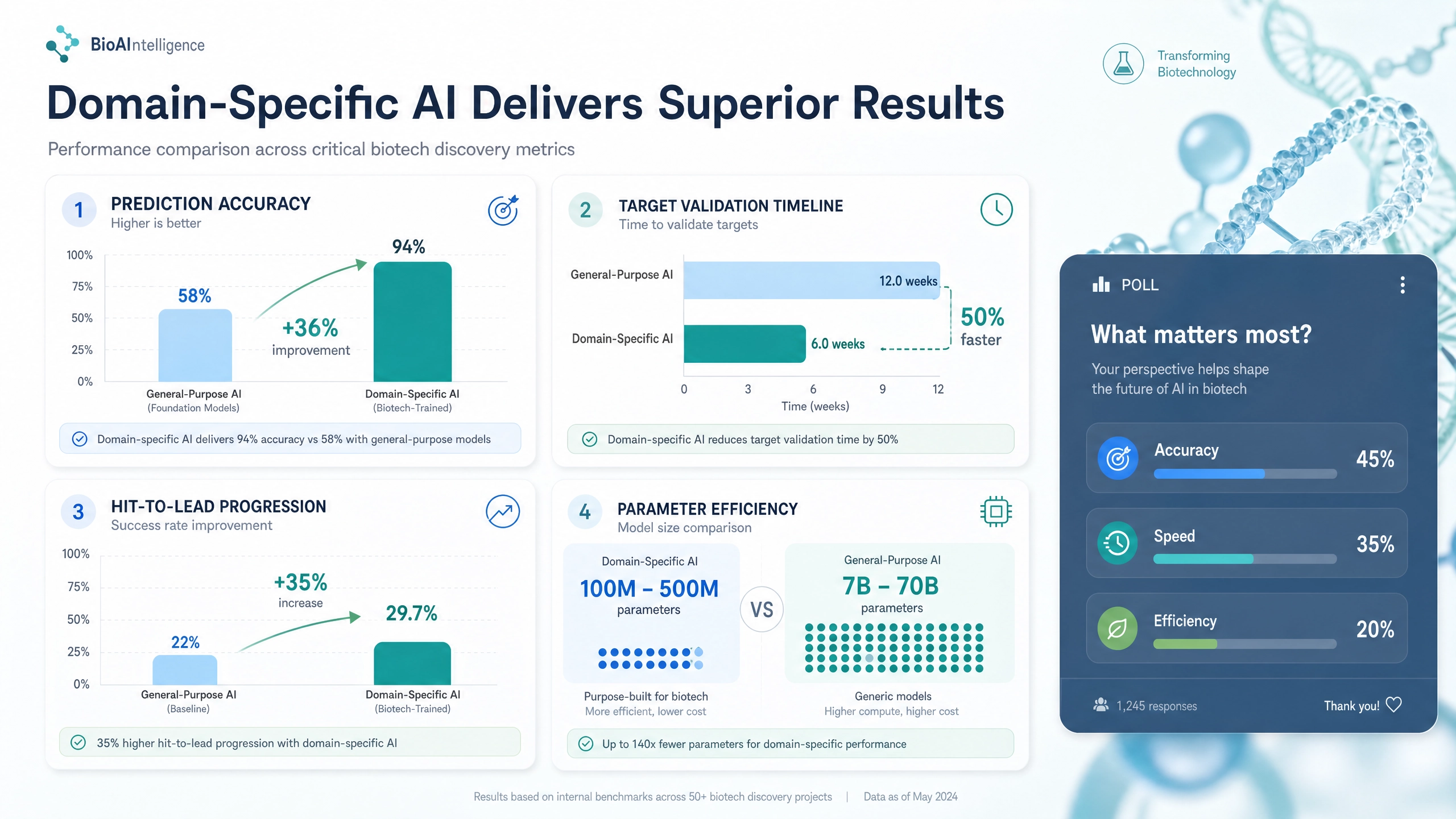
The data is compelling and unambiguous. On biomedical named entity recognition tasks—the fundamental building blocks of understanding scientific literature—domain-specific models achieve ninety-four percent accuracy compared to fifty-eight percent for general-purpose models. This thirty-six percentage point improvement is not a subtle statistical difference; it represents a fundamental gap in capability that compounds across every downstream application. When your foundation model misidentifies molecular entities, protein interactions, or pathway relationships nearly half the time, no amount of post-processing or prompt engineering can rescue the analysis.
But accuracy tells only part of the story. The performance advantages of domain-specific approaches extend across multiple dimensions that directly impact pharmaceutical R&D economics. Target validation—the critical process of confirming that a proposed biological target is genuinely involved in disease and can be safely modulated—drops from twelve weeks to six weeks. Hit-to-lead progression, where promising compounds are identified and optimized, improves by thirty-five percent. And these superior results are achieved with models containing one hundred to five hundred million parameters, roughly one hundred and forty times fewer than the seven to seventy billion parameter monolithic systems they outperform. The computational cost savings are staggering—up to ninety percent lower compute expenses, translating to five to ten million dollars in annual infrastructure savings for mid-sized pharmaceutical companies.
The real-world implications extend far beyond cost reduction. Domain-specific AI is fundamentally democratizing drug discovery. For decades, meaningful pharmaceutical AI was the exclusive province of companies with massive R&D budgets—the handful of organizations that could afford the computational infrastructure required to train and deploy general-purpose models. Adaptive AI changes this equation entirely. Biotech startups can now access capabilities previously available only to the largest pharmaceutical companies. Academic laboratories, long excluded from AI-driven drug discovery by prohibitive costs, can participate meaningfully in research. Contract research organizations can offer AI-enhanced services to clients of all sizes. Researchers in developing countries can access advanced tools that were previously geographically and economically inaccessible.
The efficiency revolution is also transforming how target validation itself is conducted. AI systems rapidly mine millions of publications to identify target-disease associations that would take human researchers months to compile. Machine learning identifies genetic variants associated with disease and links them to specific actionable targets. Predictive models simulate the effects of target modulation, prioritizing the most promising candidates before expensive wet-lab experiments begin. Safety assessment algorithms predict potential off-target effects and safety liabilities, flagging concerns early in the development process rather than in costly late-stage clinical trials.
The future of pharmaceutical AI is clear. It is not about building bigger models—it is about building smarter ones. Systems that understand the specific challenges of drug discovery, that are optimized for real-world pharmaceutical workflows, that can be deployed on standard hardware, and that produce interpretable, explainable predictions that satisfy both scientists and regulators. The efficiency frontier is not a temporary advantage; it represents a permanent shift in how artificial intelligence will serve the life sciences. The companies and institutions that recognize this transition early will hold decisive competitive advantages in the decade ahead.