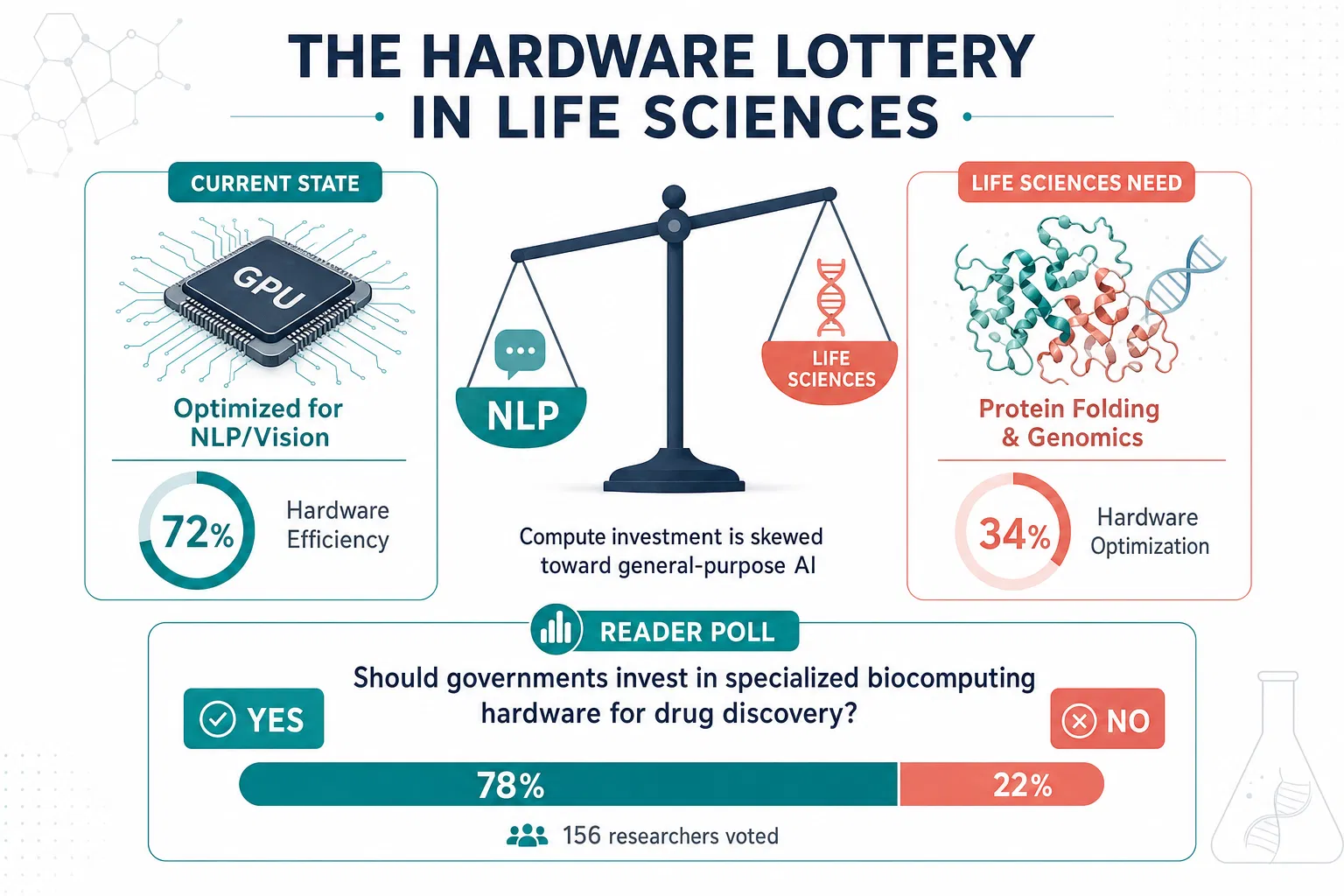
In 2020, Sara Hooker introduced a concept that would fundamentally reshape how we understand progress in artificial intelligence. She called it the "hardware lottery" — the phenomenon whereby a research idea succeeds not because it is inherently superior, but because it happens to be compatible with the available software and hardware infrastructure. The implications of this insight extend far beyond computer science. When we examine the landscape of computational biology and life sciences, the hardware lottery reveals itself as a silent arbiter of which diseases receive attention, which molecular pathways get modeled, and ultimately, which patients benefit from the promise of AI-driven medicine.
Consider the current state of protein structure prediction. The remarkable success of AlphaFold emerged not in a vacuum of pure scientific insight, but within an ecosystem of GPU-accelerated deep learning frameworks that had been optimized over a decade for exactly the kind of pattern recognition that protein folding demands. Meanwhile, equally important biological questions — such as modeling the dynamic behavior of intrinsically disordered proteins, understanding the emergent properties of cellular ecosystems, or predicting the long-term evolutionary trajectories of pathogens — remain computationally intractable, not because they are inherently harder, but because our hardware was never designed with these problems in mind.
Hooker's research now challenges this paradigm directly. Rather than accepting that biological discovery must conform to the constraints of silicon architectures designed for image classification and natural language processing, her team is building AI systems that adapt to the problem rather than forcing the problem to adapt to the hardware. This represents a philosophical shift with profound consequences for life sciences. When we stop asking "what biological questions can our current hardware answer?" and instead ask "what hardware and algorithms would we need to answer the most important biological questions?", entirely new research frontiers become accessible.
The pharmaceutical industry provides a stark illustration of this lottery in action. Drug discovery pipelines have enthusiastically adopted deep learning for molecular property prediction, largely because small-molecule representations map cleanly onto the tensor operations that modern GPUs execute efficiently. Yet the far more complex challenge of predicting drug-drug interactions in polypharmacy patients, modeling the immune system's response to novel antigens, or understanding how the microbiome mediates therapeutic efficacy — these problems demand computational paradigms that our current hardware stack actively discourages. The result is a systematic bias in which diseases and therapeutic approaches receive AI-driven innovation.
The implications for global health equity are particularly troubling. Diseases that predominantly affect populations in low-resource settings — neglected tropical diseases, drug-resistant tuberculosis, emerging zoonotic infections — often present computational challenges that do not align with mainstream hardware optimization. The biological complexity of these conditions, combined with the sparse and heterogeneous data available from affected populations, means that standard deep learning approaches trained on large homogeneous datasets perform poorly. Hooker's vision of adaptive, efficient AI systems that can learn from limited data and evolve with new information offers a potential path toward more equitable computational biology.
The hardware lottery also manifests in genomics, where the dominance of short-read sequencing technology has shaped an entire generation of bioinformatics algorithms optimized for assembling short fragments. Long-read sequencing technologies, which could revolutionize our understanding of structural variants and complex genomic rearrangements, require fundamentally different computational approaches — approaches that current hardware architectures handle inefficiently. The research ideas that could emerge from native long-read analysis remain trapped behind a hardware barrier, their potential unrealized not because of scientific impossibility but because of infrastructural incompatibility.
What makes Hooker's framework so powerful for life sciences is its diagnostic clarity. By naming the hardware lottery, she gives researchers a vocabulary to articulate why certain approaches dominate not through merit but through compatibility. This awareness is the first step toward building computational infrastructure that serves biology's actual needs rather than constraining biology to serve hardware's existing capabilities. The future of computational life sciences depends not merely on building bigger models, but on building the right computational substrates for the biological questions that matter most.